

Let's start with a disclaimer....I love Cassandra! I have used it in a couple of projects and I was always impressed by what is offering.
But I also believe that Cassandra is one of those technologies that should only be applied to specific use cases. And I assume that's where most of the hatred is coming from, teams trying to use it even though it doesn't really fit their use case.
But before I get carried away, let's first have a look at what is Cassandra and how it's working internally.
What is Cassandra
Cassandra is a highly-scalable, highly-available distributed NoSQL database. It was created at Facebook and later was open-sourced under the Apache umbrella.
It's a column-oriented database and its data model is based on Google's BigTable, while its data distribution design is based on Amazon's DynamoDB.
It's very well suited for handling massive amount of load with very good performance while offering linear scalability (the more nodes you add, the more requests can handle) and no single point of failure.
These are some of the reasons why a lot of big companies such as Facebook, Twitter, Netflix, eBay etc. are using it.
Cluster architecture
When Facebook created Cassandra, they had a specific use case in mind. It was supposed to be used in their messaging app, so their main focus was availability and not strong consistency. And it makes sense in the context of a messaging app, you care more about being able to send a message and not so much about getting every message the exact moment they are sent.
Data distribution
With that in mind, Cassandra's clusters don't have a special master/coordinator node. Nodes in the cluster are peers, they are exactly the same and clients can use any node to connect to the cluster and do reads and writes.
The nodes are logically organised into a ring. That's why we often hear the term Cassandra ring.
Each node is owning a part of the overall data that is stored in the cluster. For data distribution, Cassandra uses consistent hashing to decide the owner node of a piece of data. For hashing it uses the primary key of the data (we will discuss more about this later, when we talk about Cassandra's data model) and the Murmur3 algorithm.
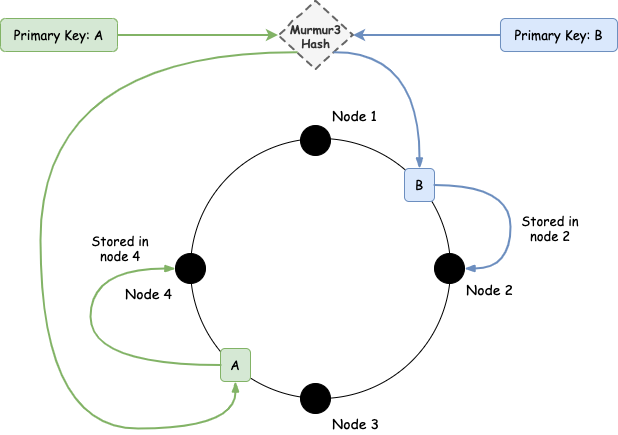
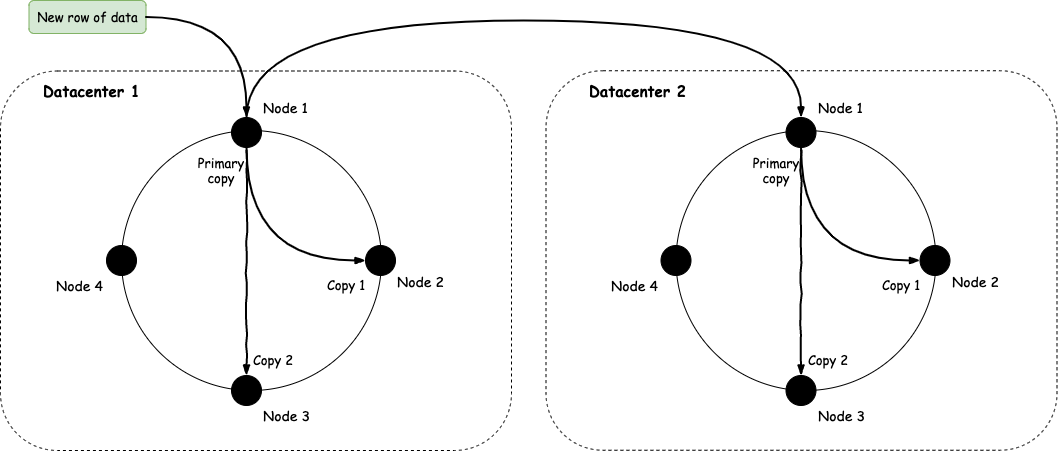
To achieve the desired availability, we need to replicate data. Cassandra's replication factor basically tells the cluster how many copies of the data it should keep. A typical value of this is 3. So, when a client sends a new piece of data to be written, Cassandra will first write it to the node that owns this data (as we showed above) and then it will send it to the appropriate nodes to replicated according to the replication factor.

In addition to the local data distribution, Cassandra also offers global distribution. In other words, it allows you to setup clusters in different datacenters, and Cassandra will take care of the distribution. This is a very popular feature of Cassandra as it allows geographic distribution of data which leads to lower latencies.
Gossip protocol
Based on what we've said so far, the following question should arise naturally:
If there is no master or special node in the cluster, and no configuration server is used, how does each node know about the other nodes in the cluster?
And the answer to this question is all the nodes in the network are using the gossip protocol.
Gossip protocol is a peer-to-peer communication protocol that is based on the actual gossip that occurs in social networks.
Basically, each node in the cluster randomly communicates with other nodes and sends information that it currently knows, for example the cluster topology. This helps Cassandra nodes achieve three things:
- It's a great way to propagate knowledge regarding the status of the cluster, which nodes are currently participating and how to reach them
- It makes node membership (new nodes joining the cluster) easy
- Provides easy healthcheck as nodes can easily detect whether another node is down or not
Consistency
Cassandra offers tunable consistency. It allows you to sacrifice performance and availability to achieve greatest consistency. Besides, as the CAP theorem states, we cannot have both strong-consistency and high-availability in a distributed system.
In Cassandra, we have a per-request consistency level. For each request, either a write or a read, the client can define how strong of consistency he/she wants. Basically, the client specifies how many nodes he/she wants to acknowledge the request before Cassandra replies back. Some of the most popular options are:
| Consistency Level | Write Request | Read Request |
|---|---|---|
| ONE | Written by at least one replica | Result of the closest replica |
| TWO | Written by at least two replicas | Most recent data from the two closest replicas |
| THREE | Written by at least three replicas | Most recent data from the three closest replicas |
| LOCAL_QUORUM | Written by the quorum of replicas in the datacenter | Result after a quorum of the replicas in the same datacenter |
| QUORUM | Written by the quorum of replicas across all datacenters | Result after a quorum of the replicas across all datacenters |
| EACH_QUORUM | Written by the quorum of replicas in each datacenter | N/A |
| ALL | Written by all the replicas | Result from all the replicas |
The further you go down in the above list, the lower the availability gets while the consistency increases. For example, in the ALL case, you get a very strong consistency, but if a datacenter or even a single replica is down, the request fails.
However, in most of the projects I've worked with Cassandra, given that it was the tool of choice because of its performance and availability and also due to the fact we could tolerate eventual consistency, we wouldn't go above QUORUM which actually strikes a nice balance between availability and consistency. In some cases, we were even using ONE.
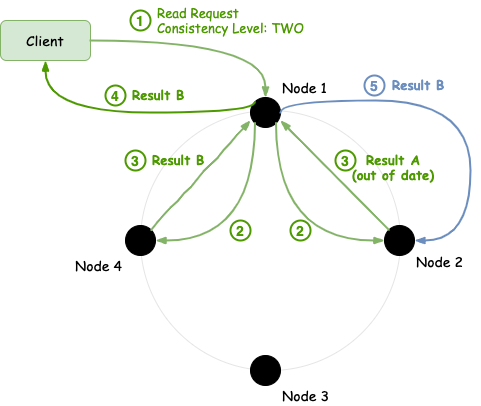
Now, let's say we have a read request that uses consistency level of TWO. And let's assume that for some reason, the two replica nodes return different results. How does Cassandra decide which data should be returned?
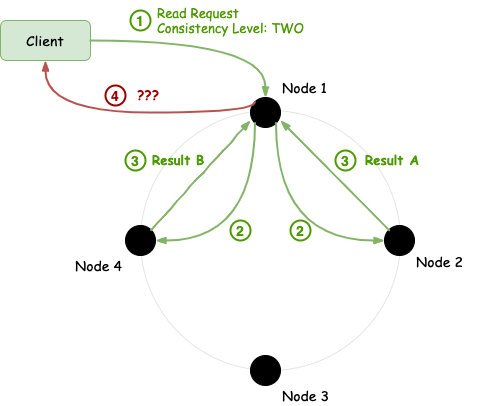
In situations like that, Cassandra uses the last write wins scheme, and picks the most recent data to return. So, in the above example, if Result B was written after Result A (i.e. node 2 wasn't up-to-date), the cluster would reply with Result B.
In addition to the above conflict resolution, Cassandra will also perform a read repair in situations like that. Basically, upon a read request, when it detects that some replicas are not up-to-date, it will try to fix them. So it will send the correct value to all these out-of-date replicas which will perform this operation like a normal write (with backdated timestamp).
Read repair is one of the anti-entropy mechanisms that Cassandra is using to make sure data is consistent. Some others that we won't see in this post are:
- Hinted-handoff: When a node goes down for a relatively small period of time, when it comes back up, the other replicas will stream to it all the additional data that were stored while the node was away.
- Repair: While read repair fixes specific data on specific replicas, repair will fix consistency issues across your cluster. It's a good practice to run this operation frequently (for example weekly) to ensure the data integrity in your cluster.
Node architecture
So far, we've seen how different Cassandra nodes in a cluster work together to serve read and write requests. But what exactly happens in each of these nodes when such a request comes in?
Let's start with the write requests.
Write path
When a write comes in, it will first be persisted to disk into a commit log. This commit log is an append-only file and contains every write request that the node receives. These entries survive even if the node goes down and they are basically used for recovery in case of failures.
The node also writes the request into an in-memory cache called memtable. This cache accumulates writes that have the same key (i.e. the same partition key) and is being used to serve reads for data that haven't been persisted to disk yet. A node has one memtable for each of its tables.
Once both of these operations happen, the node will send an acknowledgement back to the caller.
The memtable will keep accumulating write requests per key in a sorted fashion until it reaches a specific configurable limit. Once it reaches that limit, then the whole memtable is flushed to disk, in a sorted strings table called SSTable. This is a concept that comes from Google's BigTable.
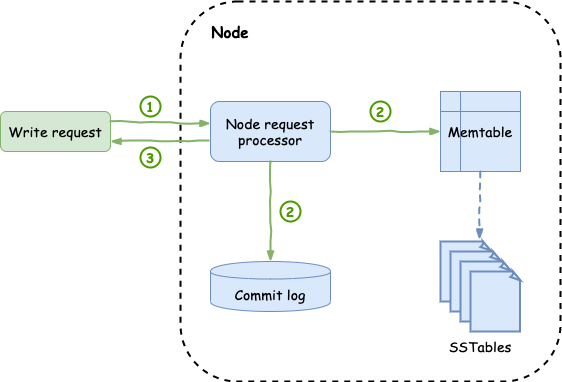
Periodically, each node will run a background process called compaction to merge the SSTables into a single one. Having a single SSTable helps with the performance of read requests. There are many different types of compaction techniques, but we won't be covering them in this post.
One thing to keep in mind is that all the above structures are append-only structures. When we update existing rows, we do not overwrite data. Instead we create new entries and we leave it to the compaction and read paths to decide which entry to use. Basically, as we saw earlier, Cassandra uses the last write wins scheme.
The same is true for delete operations. Deletes do not actually delete data, but they mark them as deleted by creating a new entry for this data called a tombstone.
Ok, let's see now how the read path works.
Read path
The read path is quite straightforward. When a read request comes in, the node will check the SSTables and the Memtables to find the data requested. Since both SSTables and Memtables are sorted by key, these operations are quite fast.
In addition to that, to avoid going to disk for every single SSTable to check if it contains data for the given key, it uses bloom filters to quickly verify whether it should hit the disk or not. A bloom filter is a probabilistic data structure that tells you whether an element is definitely not in the set or it maybe is. So, if the filter tells you that a key is not in a given SSTable, there is no need to go and check it. On the other hand, if it tells you maybe, then we need to check it since we don't know whether it is or it isn't.
Once it retrieves the data, it will aggregate them by removing duplicates and discarding older entries (keeping only the latest update) and tombstones and it will return them back to the caller.
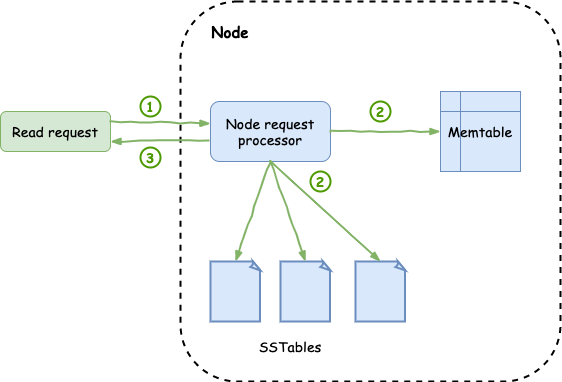
One thing to keep in mind at this point is that since both memtable and sstables are sorted by partition key, if we need to query data with something else other than the key, Cassandra will struggle. It will need to go over the entirety of the node's SSTables as well as memtables to find what you're looking for. Moreover, given that Cassandra determines the nodes that hold specific data based on the data's primary key, when we search with something else we actually have to search the entire cluster! That's why we DO NOT use Cassandra for relational modelling.
Data modelling
The way to create, insert and query data in Cassandra is by using its query language called CQL (Cassandra Query Language), which is similar to a subset of SQL.
The top-level construct of CQL is a keyspace. If we want to parallelise it to the relational world, a keyspace would be something like a database. A keyspace has a single attribute that you can define which is the replication factor. All the tables inside that keyspace will have this replication factor. And we can be as specific as we want for this, for example defining different replication for the different datacenters that we have in the cluster.
CREATE KEYSPACE my_keyspace WITH REPLICATION = {
'class': 'NetworkTopologyStrategy',
'dc1': 2,
'dc2': 3
};A keyspace can have one or more tables. Tables are consisted of columns which can be any of the supported types. Each table must have a primary key which should be unique for each row in that table.
One very important thing is that the primary key is different than the partition key. The partition key is formed from the first column that participates in the primary key of the table. This partition key is the one that determines in which node the data will be stored and also will be used for lookups within the node's Memtable and SSTables.
CREATE TABLE events(
event_address text,
event_timestamp timestamp,
username text,
PRIMARY KEY(event_address, event_timestamp)
);So, in the above example, the table events has a primary key which consists of event_address and event_timestamp. It also has a partition key which is the event_address.
Inserting and querying data is equivalent to the respective procedures in the SQL-world. The only thing to be careful though, as we've already mentioned, is that data queries must include the partition key for the reasons we explained earlier in the post.
INSERT INTO events(event_address, event_timestamp, username)
VALUES ('acquisition_1', '2020-04-13', 'antousias');
SELECT * FROM events WHERE event_address = 'acquisition_1';
Personal thoughts on Cassandra
As I've mentioned in the beginning, because of the way Cassandra is architectured, it's extremely good at certain use cases and extremely bad at others!
I have used it in the past in various projects with great success. In particular, we had a project in King where our system had to support around 1,000,000 requests per second from all around the world. Cassandra could handle that without breaking a sweat. Good luck doing that with another database.
Having said that, there are a few things you should take into account before deciding to go down the Cassandra route.
Know your queries
You should know the queries before creating your tables. Or at least have an idea of what is going to be the partition key of each table.
As we discussed earlier, the partition key needs to be part of the read requests, so that Cassandra can know which nodes to contact and also in each node to easily find the required entries. Changing from one partition key to another is an expensive and painful operation...so make sure you nail that from the beginning.
Choose partition keys wisely
Choosing the correct partition key can have tremendous impact on the performance of your Cassandra cluster.
But what constitutes a good partition key?
Ideally, partition keys should be uniformly distributed but not extremely scattered. We want to avoid hot-spots that will lead to extremely huge replica nodes, but we also want to avoid partition keys that lead to groups of just a handful of entries.
Availability or consistency?
A big factor of success with Cassandra is understanding the requirements of your use case and choosing the availability and consistency level you want carefully.
As we saw earlier, availability comes mainly from setting the appropriate replication factor in your keyspace. Consistency on the other hand comes from choosing the consistency level for each read and write queries. Some applications will need availability over consistency, while others the opposite. Remember, you cannot have both!
If you want to strike a balance between these two, the following equation is a good rule of thumb:
CL.READ + CL.WRITE > RF
where:
- CL.READ: Consistency level used for reads
- CL.WRITE: Consistency level used for writes
- RF: Replication FactorDevops are people too
One of the pain points of Cassandra is the fact that it needs careful maintenance. Although you get high availability and any failures that might happen are completely invisible to the client, this comes at a cost.
First you need to maintain your data integrity and consistency. This requires analysing your cluster topology and running repair operations frequently.
You also need to have a good understanding of how Cassandra works internally. In most cases, you won't have to deal with any internal problems. In most cases you will get the awesome speed and availability that Cassandra is known for. In most cases the cluster will recover on its own from any failures that might happen.
But, there are these rare moments....

Are you rich enough?
Last but not least, Cassandra can be really expensive!
As we saw earlier, Cassandra is using the gossip protocol for inter-node communication. This can generate a lot of messages and if you're running your cluster in the cloud can increase your monthly bills by a big factor.
Also, if you run a cluster on multiple datacenters, you should be careful on the replication factor you're using as well as the consistency level you choose for your queries. This again can generate a lot of data traffic and this time is across different availability zones, which is even more expensive.
Conclusion
Regardless of these issues, I think Cassandra is an amazing piece of technology. When a database gives you so impressive features, it is expected to have some drawbacks as well.
So, if it fits your use case, definitely give it a try. You won't regret it a bit.
But remember...
