

Systems nowadays are expected to be scalable and highly-available. They should be able to handle any load given to them (always in the boundaries of the agreed SLA) and since they usually run on cheap machines they should be fault-tolerant and always serve requests even if some of the machines die.
How do we achieve that? Well, that's easy...
Make a service stateless, startup a bunch of instances of it, and put the instances behind a load balancer.

But wait a minute....!
There are times that we actually want to make sure a certain request is routed to the same instance.
Some common use cases of this is when we use in-memory caching and we want to minimise cache misses or when the instances of the service are stateful.
Hashing...the naive way
A way to redirect a request into the same node is by using hashing. Basically, apply a hash function to a request to get a number and then somehow map this number to a specific node.
The naive and easy solution to this would be to do a modulo on the hash result with the total number of nodes we have, thus getting a number that corresponds to one of our nodes.
node_number = hash(request) mod total_number_of_nodesSo, as an example, let's assume we have a total of 3 nodes and the following 4 requests:
| Request | Hash | Node |
|---|---|---|
| A | 1337 | 2 |
| B | 1338 | 0 |
| C | 1339 | 1 |
| D | 1330 | 2 |
Let's assume now that suddenly the load increases so the autoscaler spins up one more node. Now we have 4 nodes. Let's see what happens to the above example:
| Request | Hash | Node (Before) | Node (Now) |
|---|---|---|---|
| A | 1337 | 2 | 1 |
| B | 1338 | 0 | 2 |
| C | 1339 | 1 | 3 |
| D | 1340 | 2 | 0 |
As we can see, all the requests were affected by the addition of a new node. Basically, the distribution is changing whenever we change the number of nodes.
Obviously, this is something we want to avoid. And this is exactly what consistent hashing is solving.
Consistent hashing
In consistent hashing, we think of the nodes as points on a ring (thus the name consistent hashing ring).
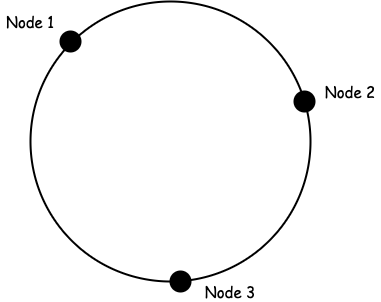
These points can be determined in various ways. For example, we could use something like the following:
node_point = hash(node_ip_address) mod 360°Then, the incoming requests are also mapped as points on this ring. In other words, instead of doing a modulo with the total number of nodes as we did before, we do a modulo with 360°.
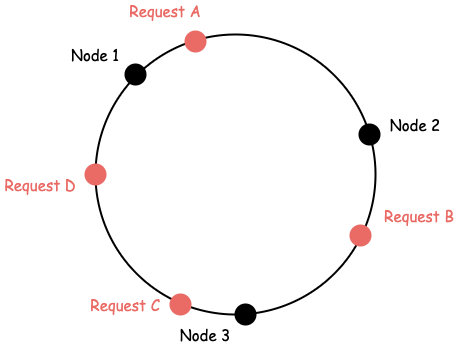
Finally, once we have a request as a point in our ring, the node that should be used for this request is defined as the next node on the ring in a clockwise order.
| Request | Node |
|---|---|
| A | 2 |
| B | 3 |
| C | 1 |
| D | 1 |
Let's see now what happens when we add a new node in the ring:
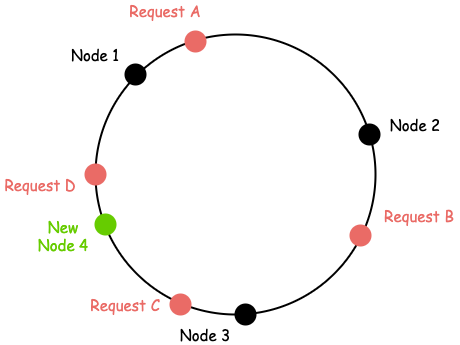
| Request | Node (Before) | Node (Now) |
|---|---|---|
| A | 2 | 2 |
| B | 3 | 3 |
| C | 1 | 4 |
| D | 1 | 1 |
We notice that, unlike before, only a single request was affected by this change, request C.
Conclusion
Consistent hashing is a great way to achieve hashing in a distributed system which is independent of the number of servers or objects in the system. It's definitely a very useful tool that any engineer dealing with distributed systems should have in his toolbox.
In fact, a lot of the modern distributed highly-scalable databases such as Cassandra, DynamoDB, VoldemortDB, and many more are using consistent hashing internally to determine the nodes that likely contain the information the user is trying to retrieve.