

The last couple of years there is a shift towards event-driven microservice architectures. More and more companies have already switched or are in the process of switching to such an architecture with Kafka being the central piece that enables communication between all the different services.
So, apparently Kafka is a thing now!

Given that I have been using Kafka extensively for the past few years, I thought it would be a good idea to provide a deeper look on what Kafka is and how it works internally.
So...what is Kafka?
Oh, if I had a dime for every different definition I've heard over the years...! Messaging system, Distributed replicated log, Streaming platform and many many more.
Well, all of them are correct, but personally I don't think they give an exact definition of what Kafka actually provides. When I'm asked this question, I find it easier to answer as:
Kafka is a distributed, persistent, highly-available event streaming platform with publish-subscribe messaging semantics.
Long one, isn't it? Well, Kafka is complicated and I feel this definition gives it justice. Let's try to break it apart, shall we?
Event Streaming Platform
Kafka is a platform that provides a never-ending series of events. Usually you will see it in a system architecture as the central piece where all the different events that occur in the system are published. These events could really be anything, from user clicks, sensor readings, payment reports, you name it.
Distributed
Kafka is a distributed system, it doesn't run on one machine (although it can, but why would you do that to yourself?). In fact, Kafka is a cluster of machines. Each machine in a Kafka cluster is called a broker.

Brokers are basically responsible for handling requests of new events, storing events and serving them to services that request them. They also have additional functionalities, e.g. leader partition election, but more on this later.
So, if Kafka is a cluster of machines, how does each broker know which other brokers are in the cluster? The answer is Zookeeper. Zookeeper acts as a centralised service that is used to maintain naming and configuration data. So, at this point, Kafka clusters rely on Zookeeper for member discovery.
Persistent
Events that are published to Kafka are persisted in disk. This means, that even if a broker goes down for any reason, when it starts up again, it will still have the events that received before shutting down. More details on how brokers store events on disk will follow on a subsequent post.
Highly Available
Data in Kafka are replicated across multiple brokers. This basically means that even if a broker that holds some data goes down, the data is still available to be consumed by its replicas οn the other brokers.
Publish-Subscribe Messaging Semantics
One very smart thing that the architects of Kafka did, was to design it with publish-subscribe messaging semantics. On one side we have producers publishing messages to Kafka and on the other side consumers consuming these messages.
This was one of the reasons that really helped the adoption of Kafka, because despite its internal complexity, it provides a well-understood and widely-adopted pattern that almost all developers are familiar with.
Topics and partitions
Disclaimer: From now on, I will be using the terms messages and events interchangeably to describe data that are flowing through Kafka.
So, how are events stored in Kafka?
Events are stored in what we call partitions. You could think of partitions like log files (actually that's exactly how the data is stored as we will see later). Each partition is an ordered, immutable sequence of messages that is continually appended to. The messages on each partition are assigned an offset, a sequential id that uniquely identifies the message within a partition. This offset is used by the consumers, but more on that in a later post when we look at producers and consumers in mode detail.
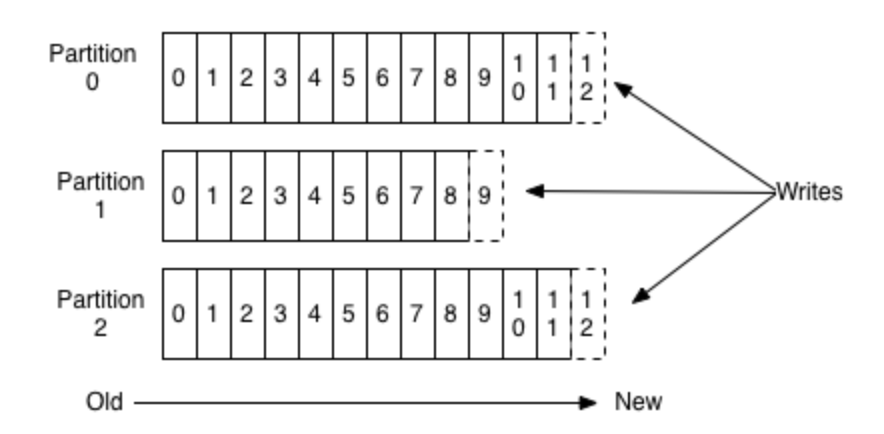
The partitions are further organised into logical groups that are called topics.
Basically, when a producer publishes a message to Kafka, he publishes it to a certain topic. Kafka will decide on which partition of that topic this message will be stored.
But wait, how does it decide which partition to be used?
This is the role of the partitioner. The partitioner will receive a message and it will decide on which partition of a topic it should be sent to. The published message is actually a key-value pair, where the value is the actual data of the message and the key can be anything that makes sense for this event. So, the partitioner will use the key part of the message to make the partition decision. Kafka producers provide default partitioners, but as with everything in Kafka, this is configurable.
The default partitioner guarantees that all messages with the same key published to the same topic, will end up in the same partition. There is however an exception to this rule and this has to do with messages with null key. If you don't supply a key, then the default partitioner will use a round-robin algorithm and will send each message to a different partition.

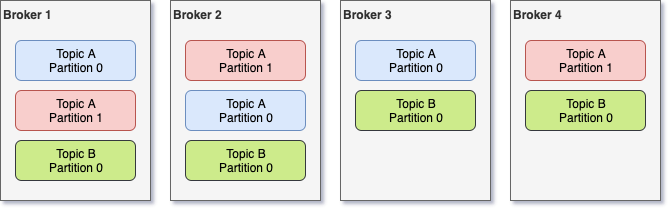
As we mentioned above, messages in Kafka are replicated to provide high-availability. In reality, the partitions are the ones that are replicated across different brokers. So, if for example you have 1 topic with 3 partitions and a replication factor of 3 (i.e. 3 replicas for each partition), you end up with 9 partitions scattered around the different brokers in a Kafka cluster. As you would expect, replicas of the same partition cannot be stored in the same broker, in other words the replication factor can only be as high as the number of brokers you have in the cluster.
Let's take an example. Let's suppose we have the following setup:
- 4 brokers
- two topics, A and B
- topic A has 2 partitions (partition 0 and 1) with replication factor 3
- topic B has 1 partition (partition 0) with replication factor 4
This could look like that:
At this point you might be wondering, what happens if we have two producers that are trying to publish to the same partition but in different brokers? In other words, what happens if we have the following scenario, how would Kafka resolve such a conflict and keep the replicas in-sync?
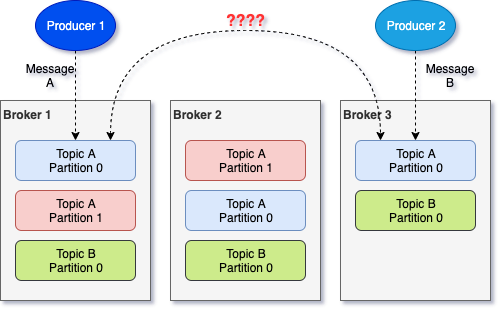
And the answer to this is: leader partition. You see, for every partition there is one replica that acts as the leader and the rest of the replicas of the same partition are the followers. When a producer wants to publish a message to a partition, it will need to send it to the leader replica for that partition. If it sends it to a follower, then it will get an error back. Once a leader replica receives a new message, it will forward it to the followers.
So, the above scenario is not valid. What happens in reality is something like the following.
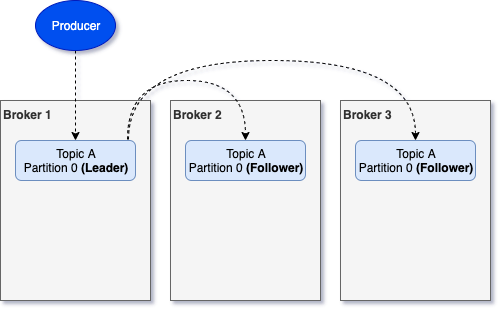
Kafka's scalability comes from the fact that it tries to assign leaders for the different partitions as evenly as possible in the available brokers. This way, producers that are trying to write to different partitions will send their requests to different brokers.
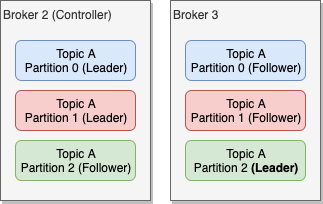
But what happens if the broker that has a leader partition dies? In that case, there will be a new leader elected from the available replicas. One of the brokers in the cluster has the additional role of Controller. This broker-controller is constantly monitoring the rest of the brokers and if it spots a dead one, then it will re-assign any available follower replica as leader for every leader replica that was on the dead broker.
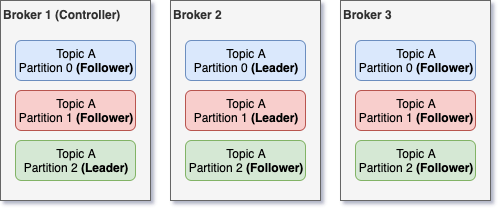
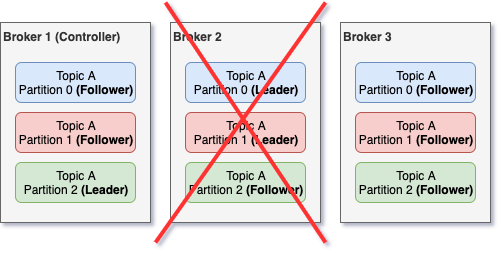
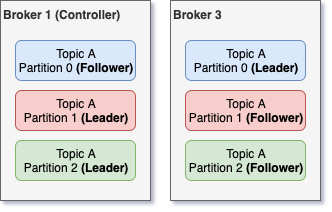
Then, the next obvious question is what happens if the broker that died is the controller? Then there is an election on the remaining brokers to decide which one will be the next controller. This election is being done via Zookeeper. More specifically, the first of the available brokers that will call the /controller path in Zookeeper will be the next controller. This approach provides some minimal guarantees that the next controller will be the broker with the least load, since it was the one that managed to contact Zookeeper first, while the others might have been serving requests.
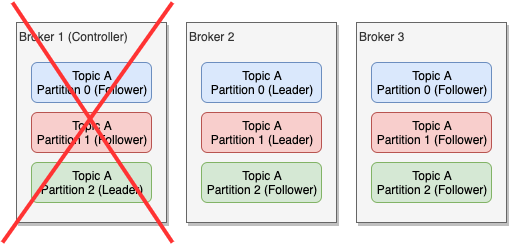
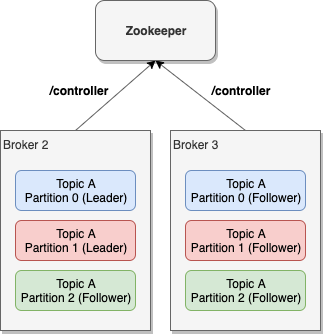
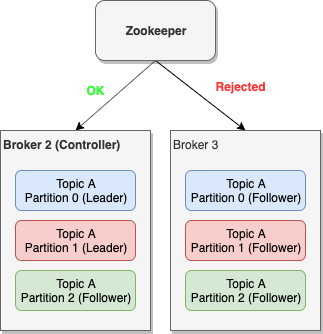
With Kafka being a distributed platform, you can expect lots of corner cases. One corner case worth mentioning here is what happens if followers are not in-sync with the leader when the leader dies. There are cases where a broker might be too busy or too slow and thus it cannot keep up with the rate that the leader is accepting messages. In that case we say that the replica is out-of-sync.
In fact, Kafka maintains an in-sync replica set (ISR) for every partition. If a replica gets out-of-sync with the leader of the partition, then it is removed from the ISR of that partition.
When a leader dies, the controller will try to choose one of the replicas in the ISR of that partition to be the new leader. If the only replicas that are available are not part of the partition's ISR, then we call it an unclean leader election. In that case, there is a chance that there might be some data loss. Of course, Kafka will try its best to reconcile the data once the broker with the additional messages comes up online, but this doesn't always work. As we will see when we talk about configuration, you can decide to disable unclean leader election and in that case, if the leader dies and the only available replicas are not in the partition's ISR, Kafka will reject any new messages going to that partition.
Try it out
Now that you have a better understanding on what Kafka is and how messages are stored, it would be a good idea to try it out.
First, you will need to download the latest version of Kafka. At the time of this post, the latest version of Kafka is 2.3.1.
Next, unzip the tar file and move into the newly created directory.
> tar -xzf kafka_2.12-2.3.1.tgz > cd kafka_2.12-2.3.1As we saw earlier, Kafka is using Zookeeper for cluster membership. So the next step is to start Zookeeper. For now, we'll use the default properties that come along with the Kafka distribution you downloaded.
> bin/zookeeper-server-start.sh config/zookeeper.propertiesFinally, we can start our Kafka broker. As with Zookeeper, we will be using the default properties for the broker. You could start multiple of these if you want to try out a cluster with multiple brokers, just make sure to give to each one a different broker id, a different port and a different path for its data.
> bin/kafka-server-start.sh config/server.properties --override broker.id=1 --override listeners=PLAINTEXT://:9092 --override log.dirs=/tmp/kafka-logs-1Now that we have our Kafka cluster up and running, we can create a topic with name all_about_coding that has 2 partition with replication factor 1. Remember, the replication factor can only be as high as the number of brokers you have in the cluster.
> bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 2 --topic all_about_coding > bin/kafka-topics.sh --list --bootstrap-server localhost:9092 >> all_about_codingThe Kafka distribution comes with a sample producer and consumer to play around with. The producer is a command line client that receives input from standard input and send it to Kafka. So let's try startup the producer and send two messages.
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic all_about_coding >> Deep dive into Kafka (part 1) >> Deep dive into Kafka (part 2)Finally, we can start the consumer and consume the messages that already exist in the all_about_coding topic. The consumer that comes with the Kafka distribution just reads all messages from a given topic and dumps them on the console.
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic all_about_coding --from-beginning >> Deep dive into Kafka (part 1) >> Deep dive into Kafka (part 2)Conclusion
I think this is a good point to stop as the post grew quite longer than I anticipated.
I hope you now have a clearer picture of what Kafka provides and how topics and partitions work internally.
In the next post we'll take a closer look at the producers and consumers, as well as the deliver guarantees that Kafka provides.