

In the previous post we saw how Kafka topics and partitions work. Let's now have a closer look at how producers and consumers publish and consume messages respectively. Finally, we'll talk about the different delivery guarantees that Kafka provides and how we can configure each one of them.
Producers
A producer is an application that publishes messages to a Kafka topic. A message is essentially a key-value pair, where the key is used to identify the partition of the topic that the event will be published to and the value is the actual message.
Pretty simple, huh? Although Kafka is a very complicated system in its core, all this complexity is hidden away and its producer and consumer abstractions are very easy to grasp and simple to use.
Producer Internals
In order to create a producer, you need to supply the following configurations:
- bootstrap.servers: Connection details for at least one of the Kafka brokers in the cluster. By connecting to one broker, you essentially connect to the whole cluster. It's actually a good practice to supply more than one broker, in case one of them is down.
- key.serializer: The serialiser class which converts the key of a record to a format understood by Kafka.
- value.serializer: The serialiser class which converts the value of a record to a format understood by Kafka.
There are more configuration that you could supply upon creation of the producer, but these are the most common ones. You can find a detailed list of all producer configuration here.
Internally, a Kafka producer looks something like the following:
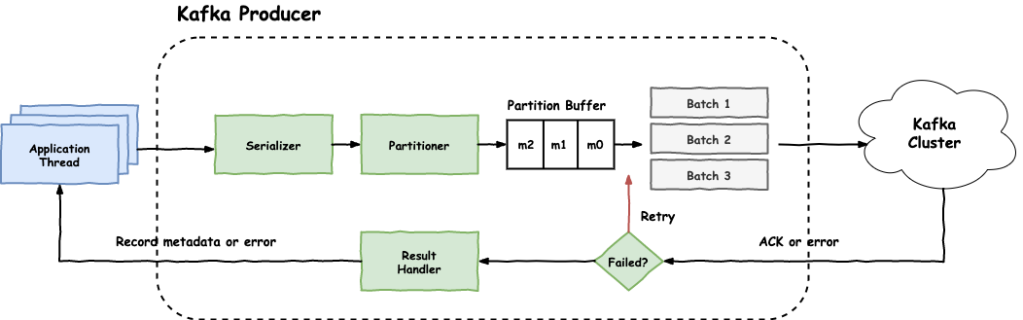
The application (i.e. application thread) creates a ProducerRecord which sends to the producer by calling producer.send(record). The producer record contains information like the following:
- topic: The Kafka topic that the message will be sent to
- key: The key is used to determine to which partition of the topic the message will be sent to
- value: The actual message we want to send to Kafka
- partition: Optional property in case we want to explicitly specify the partition
- timestamp: The timestamp of the record as milliseconds since epoch
- headers: Any headers to be included along with the record
There might be more or less properties, depending on the Kafka client's implementation. The only mandatory properties though are the topic and the value. But it's good practice to always use a key as well, to control the partitions that each record will end up.
Serializer
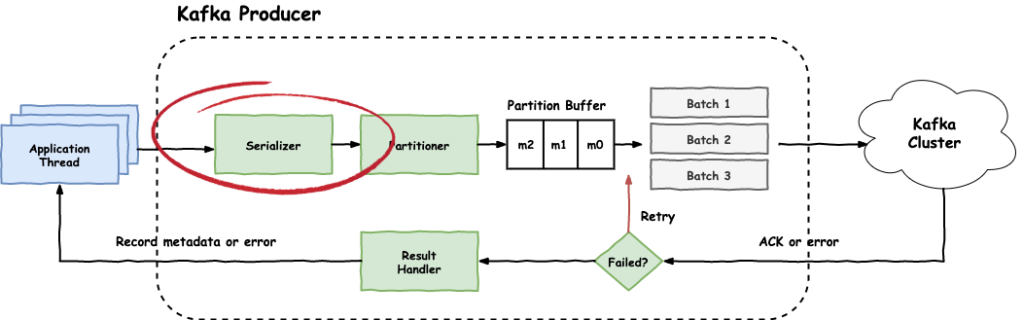
Once the producer receives a record to be published, it uses the Serializer to convert it to Kafka's message format. The message format that Kafka is using is configurable upon creation with a variety of options to choose from. Some of the most popular options are:
- JSON: Textual format, common format used by browsers/API endpoints
- Avro: Binary format, thus non-human readable but also more space-efficient. Allows easier schema evolution via Schema Registry
The type of serialiser that the producer is using is defined upon the creation of the producer using the following configurations: key.serializer and value.serializer.
Partitioner
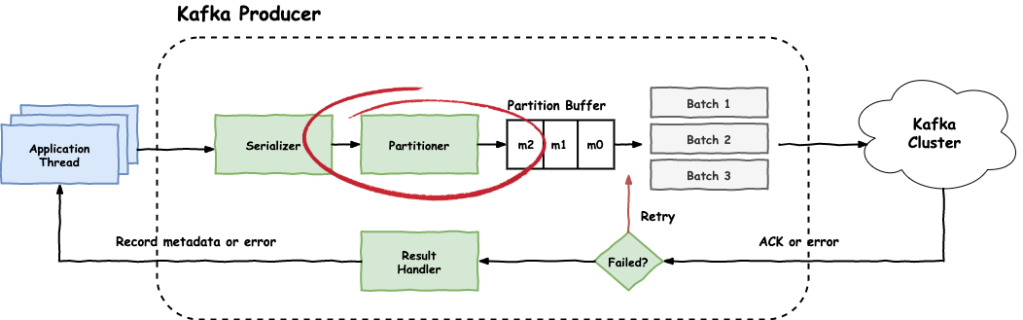
The next step after serialisation is the Partitioner. At this stage, the producer determines to which partition of the topic, the record should be sent to. By default, the DefaultPartitioner will be used, which follows these rules:
- If there is a partition number defined in the incoming record, then that partition is used.
- If there is a key in the incoming record, then use
hash(record.key) % num_partitions. - If there is no partition number and no key, choose a partition in a round-robin fashion.
In most cases, the default partitioner works just fine. But there might be cases where you want to control the partitioning logic, for example we might want to split certain keys to several partitions just to avoid hotspots. The producer's configuration value that allows us to override the partitioner is partitioner.class.
Buffers and Batches
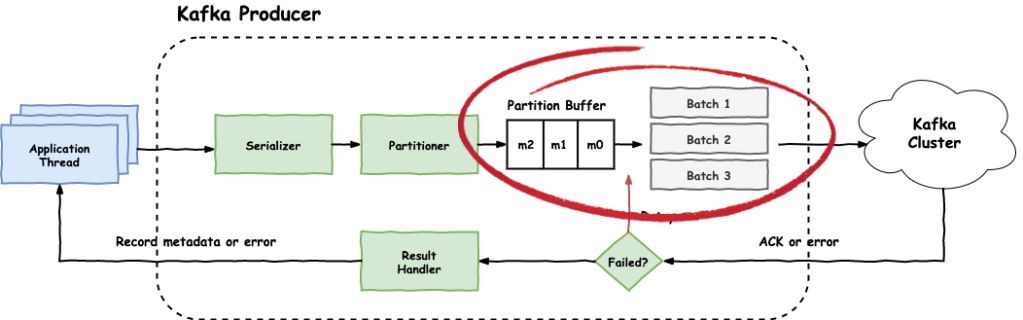
Once the partition of the record is determined, the record is placed into the partition's buffer. Basically, the producer will try to batch records for efficiency, both IO and compression. These partition buffers also help with back-pressure, since the records will be sent as fast as the broker can keep up, which is configured by max.in.flight.requests.per.connection.
To increase the producer's throughput, it's a good practice to set linger.ms to a value greater than zero. This basically instructs the producer to wait up to this number of milliseconds before sending the contents of the partition buffer, or until the batch fills up (whichever of the two comes first). The batch size is configured by batch.size.
So under heavy load, the batches fill up quickly so the linger time is not met...under lighter load, the producer uses this lingering time to increase IO throughput.
Reliability and Retries
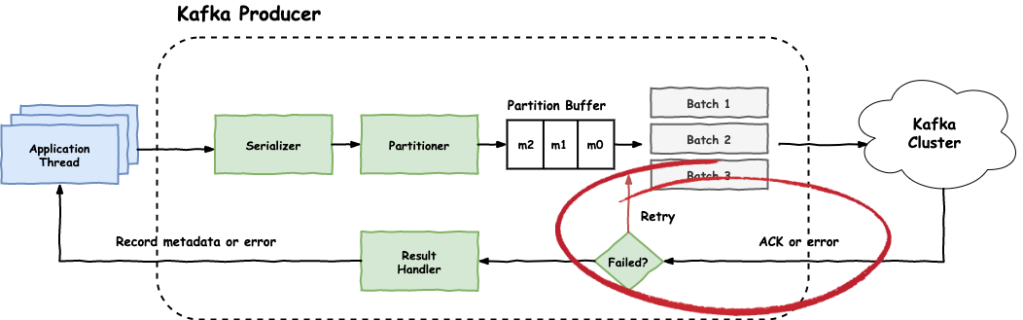
One important aspect that we need to consider when configuring a Kafka producer is its reliability. In other words, what degree of confidence we want to have so that when we publish a message to the cluster, the message is not lost.
The reliability of a producer is achieved via the acknowledgement (ACK) configuration request.required.acks.
When we set this value to 0 , i.e. ACK-0, is equivalent to fire and forget. Basically the producer will place the record in the partition buffer as we saw above and it will never check whether it was successfully persisted in the Kafka cluster.
You might ask, why would anyone choose this option?
And the answer is low-latency.
Since the producer doesn't wait for Kafka's acknowledgement, it's very fast.
This is particularly useful for applications where we have high-volume and we don't really care whether some of the data is lost. Such examples are IoT applications where we don't really care if we lose readings from some of the sensors.
Another option is to set the required acknowledgements to 1 (ACK-1). This is also called leader acknowledgement and it means that the Kafka broker will acknowledge as soon as the partition leader writes the record in its local log but without confirming that the partition followers got the record. As you can imagine, if the partition leader fails immediately after sending back the ack but before replicating the record to its followers, we might have data loss. That's why we usually use this option if a rarely missed record is not very significant, for example log aggregation, data for machine learning or dashboards, etc.
The final option is all (ACK-ALL). In this case, the leader gets write confirmations from all in-sync replicas (ISRs) before sending an acknowledgement back to the producer. This ensures that as long as there is one ISR alive, the data is not lost.
Finally, producers can be configured to retry sending failed messages by setting the configuration value of retries to the maximum number of retries for each failed message. By default the retries is set to 0. One thing you should note though is that if you set the retries to a value greater than zero, then you should also set the max.in.flight.requests.per.connection to 1, otherwise there is a chance that a retried message could be delivered out of order.
Consumers
The last piece of the puzzle to complete our end-to-end flow is the consumers.
As someone would expect, consumers read data from a Kafka topic. In order for a consumer to start reading from a topic, it needs the name of the topic and at least one of the cluster's brokers to connect to. As with producers, once it connects to one broker, it is connected to the whole cluster. Also, as with producers, it doesn't need to connect to the broker that holds the data, Kafka will take care of that.
As we mentioned many times already, a topic is just a logical grouping of partitions. So, consumers actually read data from partitions. But again, Kafka will take care of that, the developer doesn't need to worry about it.
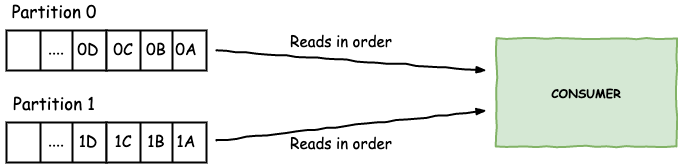
One thing to note though, is that the consumer will read data from the same partition in the order they appear on the partition, but different partitions will be read in parallel. For example, in the picture above, consumers will always read 0A before 0B and the same for 1A and 1B. But the order in which it reads 0A and 1A might differ each time.
Consumer Groups
Consumers are organised into consumer groups. This way we can parallelise the data consumption.
A very important thing to understand is that each partition of a topic is read by one and only one consumer in a consumer group! Let me repeat that...in a consumer group, a partition is read by a single consumer.
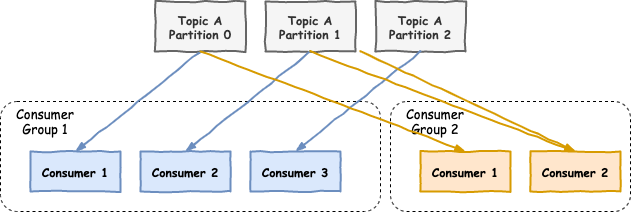
As we can see in the above example, each partition is read by one consumer in each partition group, but each consumer can read multiple partitions.
The reason of having a single consumer responsible for a partition in each consumer group is that messages in a partition are read in order.
So what happens if we have more consumers than partitions in a consumer group?
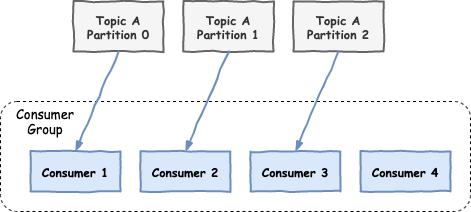
The answer is that the extra consumer is not being used and is on standby mode, ready to be utilised if one of the other consumers fail.
This basically means that the level of parallelism and the scaling of Kafka is defined by the number of partitions we have. The more partitions we have in a topic, the more consumers we can use for that topic.
Rebalancing
But how do consumers enter and exit a consumer group? How do they know which partition to read when they join or how are partitions assigned to other consumers if a consumer exits the group?
When a consumer group is created, one of the brokers in the Kafka cluster is elected to be the group coordinator. In addition to that, the first consumer that joins the consumer group, becomes the group leader. Through the coordination of these two, it's possible to detect changes in the group and re-assign partitions to consumers.
This action of reassigning partitions to the consumers in a consumer group is called rebalancing. The rebalancing process can be described as follows:
- A new consumer joins the group and wants to read from the topic.
- The group coordinator (elected Kafka broker) detects the new consumer that tries to read and sends a list of all the consumers trying to read, to the group leader (first consumer that joined the consumer group).
- The group leader decides the partition assignments and sends them back to the group coordinator.
- The group coordinator sends this information to all the consumers.
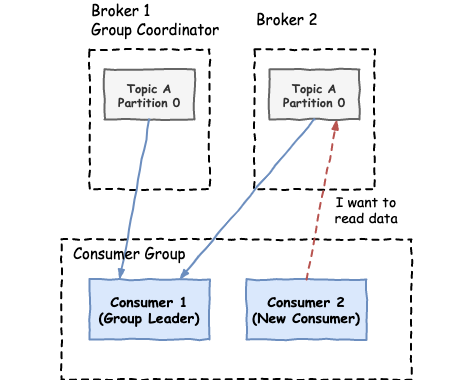
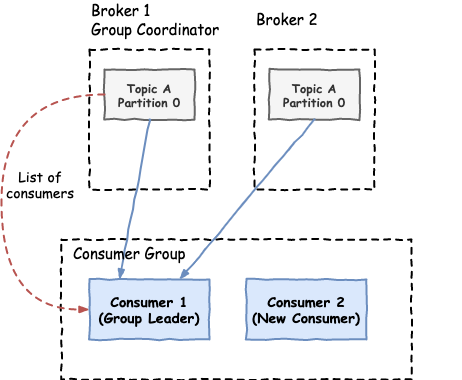
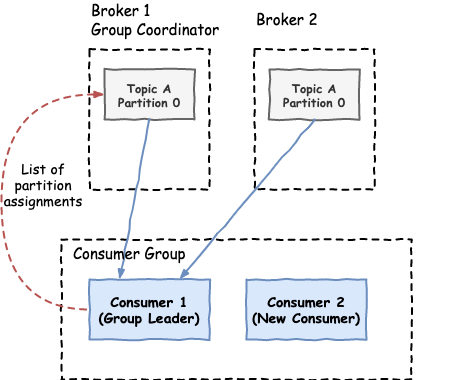
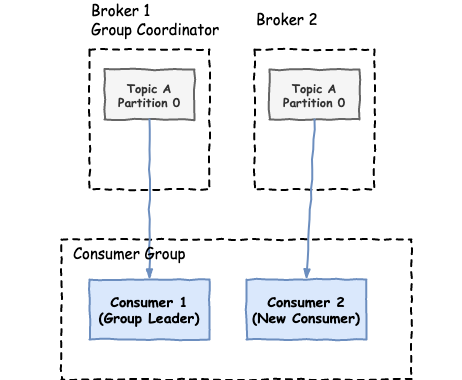
One thing to keep in mind is that while rebalancing is happening, all the consumers stop reading from their partitions. Frequent rebalancing is a common cause for performance degradation in Kafka consumer applications and it should be monitored and avoided if possible.
Consumer Offsets
Now we know what happens when a new consumer joins a consumer group or when an existing one leaves. But wait, does this mean that we'll have a bunch of duplicate events because the new consumer will re-read the whole partition?
The answer of course is no. The consumer will start reading from the point of the partition that the previous consumer stopped. And this is achieved with consumer offsets.
Basically, consumers will commit the offsets they have read back to Kafka. Kafka keeps track which offsets of a partition have been read by a particular consumer group. This information is kept in a separate topic called __consumer_offsets. So, once a consumer of a particular consumer group is assigned a partition, Kafka will check which was the latest committed offset of that partition for this consumer group, and will send the next offset.
The main question is, when should a consumer commit an offset?
It could commit it once it receives the message from Kafka and before does the actual processing of the message. The problem is that in this case, if for some reason the consumer dies after it commits the offset and before the processing, then we lose the data. The next consumer will not see this message again.
Alright, then it could commit it after it processes the message. But what happens if the processing is complete (for example, the message is transformed and some local database is updated) but the consumer fails right before it commits the offset? In this case, the new consumer that will take over will re-receive the message and it will process it again. So, we're getting duplicate messages.
Which way to go depends on your application use-case, but in most cases the correct thing to do is the latter. You just need to make sure in your application logic that your message processing is idempotent.
Delivery Guarantees
Now that we know how messages are published and consumed from Kafka as well as how they are stored internally, it's time to talk about the delivery guarantees that Kafka provides. As we have seen already, Kafka is a highly configurable system. As such, you can configure it in a different way to achieve different delivery semantics depending on your use case.
At most once
This setup basically ensures that a message published by a producer into the Kafka cluster will arrive zero or one times into the consumer, but not more than that! This guarantees that there will not be any duplicate messages, but there might be some data loss.
It's quite useful for applications where we have high volume of data and some data loss is acceptable. An example application space is IoT applications.
To achieve at-most-once deliveries, first we need to configure the producers so that they don't retry sending messages to the cluster. The best way achieve at-most-once semantics in a producer is to set request.required.acks to 0.
In the consumer side, we're in luck as at-most-once delivery is the default behaviour. In general, to achieve this, we just need to set the enable.auto.commit to true. This basically informs the cluster that a message has been read (i.e. commits the offset) as soon as the consumer receives the message and before processing it.
By default, to avoid performance impact, consumers will try to batch as many offset commits as they can and commit them all at once. The amount of time the consumer will wait before committing the offset is configurable by auto.commit.interval.ms. So, in the case of at-most-once, we need to set this to the lowest timeframe possible, to make sure that the offset is committed before the processing of the message.
At least once
This ensures that a message published by a producer will definitely arrive to the consumer, but it might arrive multiple times. It is probably the most common setup, as it guarantees no data loss and it's not as hard to achieve as the exactly-once case that we'll see next.
First, the producer needs to make sure that a message is safely persisted in the cluster. This is achieved by setting the request.required.acks to all, telling the leader partition to only notify us for success if the message is stored in the leader's and the followers' logs.
In addition, the producer needs to retry sending a message if it doesn't hear back from the Kafka cluster, or if the cluster replies with an error. So, we need to set the retries to a number greater than zero.
Finally, in the consumer side, we need to disable the auto-commit by setting the enable.auto.commit to false, as this could lead to data loss in the case where a consumer commits its offset and then fails before processing the message. Since auto-commit is disabled, the consumer needs to do the offset management by explicitly calling the consumer.commitSync() after the processing of the message is complete.
Consumers with at-least-once semantics, need to handle duplicate messages that may arrive. This can be done by implementing the consumer to have idempotent behaviour.
Exactly once
At this point, those of you who have worked with Kafka or have experience with distributed systems might be thinking that exactly-once delivery in such an environment is impossible or it comes with such a high price that is not practical.

In all the years I've been working with Kafka, I've never seen any real-life producer-consumer systems that uses exactly-once delivery. Most projects tend to stay with at-least-once semantics and implement an idempotent behaviour in the application.
Having all that in mind, let's see how we could achieve exactly-once delivery.
On the producer side, we need to ensure that the messages we send to the cluster are persisted. As we saw on the at-least-once case, this can be achieved by setting the request.required.acks to all and the retries to a value greater than 0.
Of course, this might lead to duplicate messages when a message is successfully persisted in the cluster but the broker dies right before it sends back the acknowledgement, or there is some network failure and the acknowledgement is lost. In that case, the producer won't know that the message was persisted successfully, so it will re-send it, creating this way duplicate message. To avoid that, we need to set enable.idempotence to true.
On the consumer side, things are a bit different depending on whether you're using the consumer API that we saw in this post, or you're using Kafka stream processors (which we'll look in a later post).
Good news first....if you're using stream processors to consume and process your messages, then exactly-once is a simple configuration change. More specifically, we just need to set processing.guarantee to exactly_once in our stream configuration.
If, on the other hand, you're using the Consumer API, things are a bit trickier. You will need to use the transactions API. First, on the producer side, you need to set a unique transactional.id and publish messages as follows:
[code language="java"] producer.initTransactions(); try { producer.send(record); producer.commitTransaction(); } catch (KafkaException e) { producer.abortTransaction(); } [/code]
On the consumer side, you will need to set the isolation.level to read_committed.
In general, Kafka allows exactly-once delivery but it comes with cost in throughput, latency and also complexity. So my personal advice would be, go with at-least-once semantics and handle duplicate messages on the application level.
Conclusion
Phew, that was long! Kudos to all of you who stayed until the end.
This concludes our deep dive to Kafka. I hope you learned something from all of this.
I hope your takeaway is that although Kafka is a very complicated system and there are a lot of corner cases you need to think about, its abstractions are clear and quite easy to use.